From notebook to production: what ML Zoomcamp actually taught me
Just completed my ML Zoomcamp capstone — and I learned more debugging production issues than I did training models.
A bit of context: I’ve spent a good chunk of my last few years building ML models in financial services. Model development is familiar territory. At work, we convert notebooks to .py files and hand them off to the engineering team. I’ve always wanted to own that last mile myself.
I started looking at bootcamps to fill that gap. Most of the options I found were either too expensive, too rigid in schedule, or too shallow in content. Then I found ML Zoomcamp — free, self-paced, and genuinely rigorous. It was exactly what I was looking for.
ML Zoomcamp by DataTalks.Club is a free 4-month program taught by Alexey Grigorev that covers the full ML engineering stack:
📐 Part 1 — ML Foundations (don’t let the name fool you — the content goes deep)
• Linear & logistic regression
• Decision trees & ensemble methods (Churn prediction)
• Neural networks with TensorFlow and PyTorch (Image recognition)
• Model evaluation and feature engineering
⚙️ Part 2 — Production Deployment
• Building APIs with FastAPI
• Containerization with Docker
• Serverless deployment with AWS Lambda
• Scaling with Kubernetes
No paywalls. All materials on GitHub/YouTube. If you’re a data scientist who wants to stop handing off and start shipping — this is the course.
―
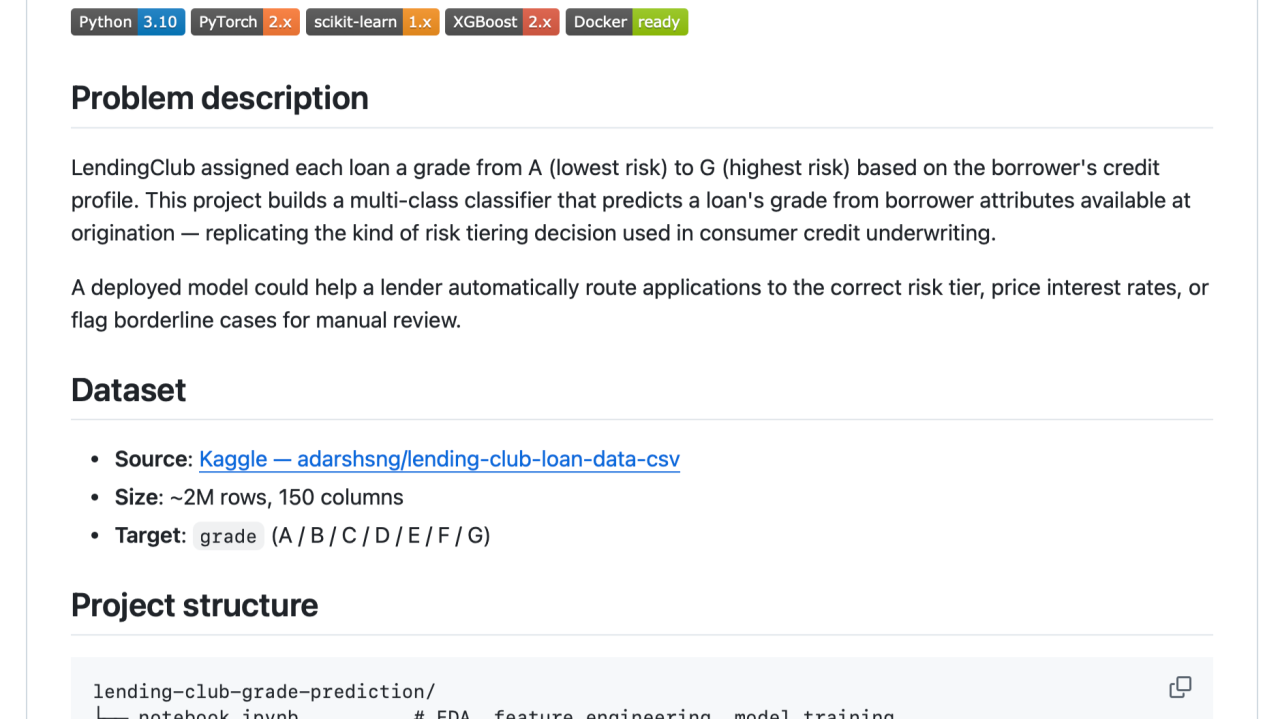
For my capstone, I tackled a problem close to my day job: predicting LendingClub loan grades (A–G, lowest to highest risk) from borrower attributes at origination — the same risk tiering logic used in consumer credit underwriting.
What I built:
• EDA on 500K+ loan records across 150 columns
• Three models: Random Forest → XGBoost → PyTorch MLP
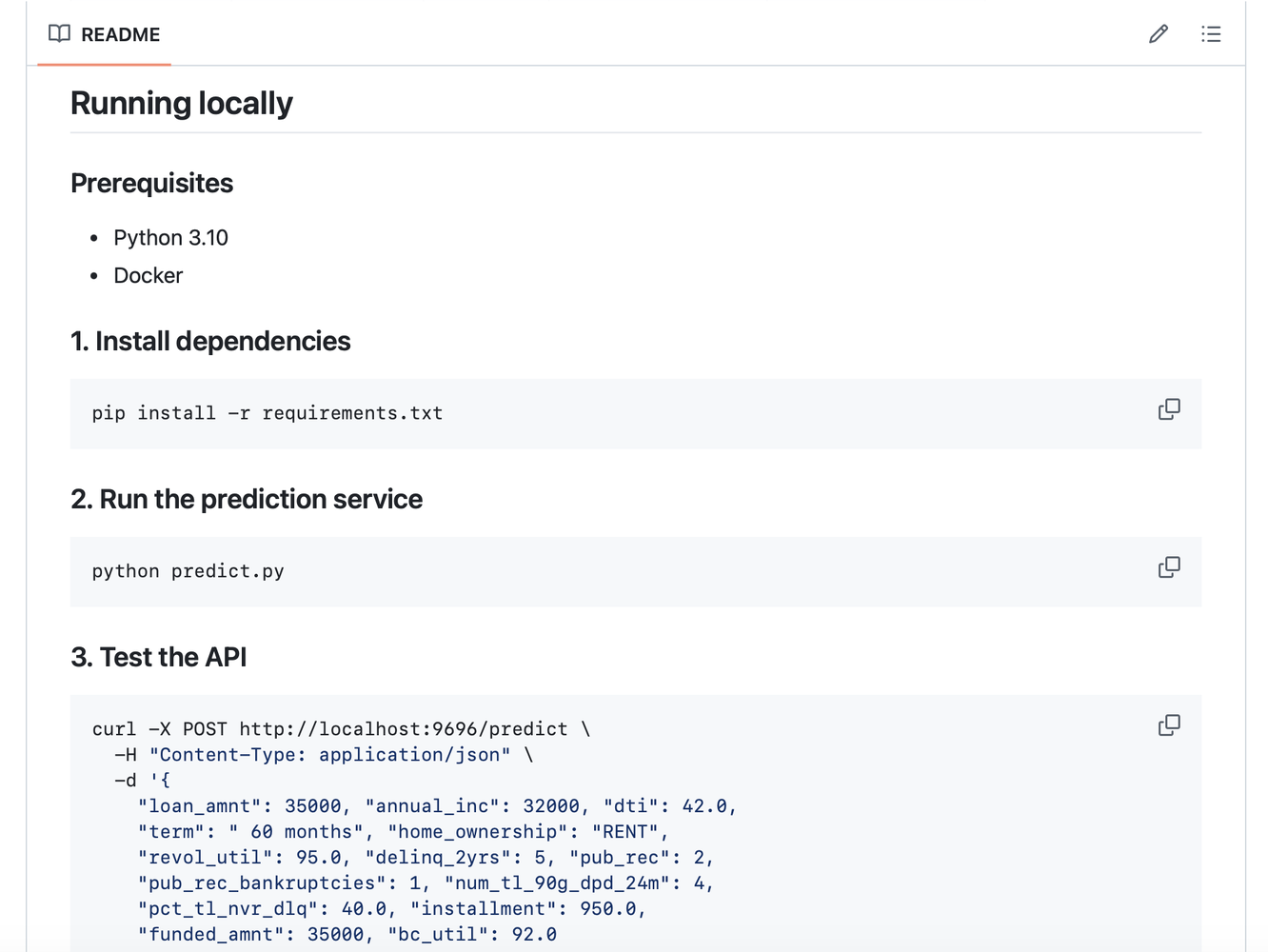
• FastAPI prediction service containerized with Docker 🐳
• Deployed live on Railway via Docker image — fully accessible from a public URL
Model results (test set, 100K samples):
• Random Forest: 0.52 weighted F1
• XGBoost: 0.94 weighted F1
• PyTorch MLP: 0.95 weighted F1
The model training was the easy part. The deployment is where I actually learned things:
1/ Data leakage is sneaky in financial data. Features like loan_status and total_pymnt look predictive — until you realize they only exist after the loan is already graded. Removing 18 leakage columns dropped raw accuracy but made the model actually deployable.
2/ Feature scaling is non-negotiable for neural nets. Unscaled features with very different magnitudes — like annual_inc in the hundreds of thousands next to dti in the single digits — cause unstable gradients and training collapse. StandardScaler fixed it.
3/ More data beats fancier architecture. Going from 75K to 500K rows improved macro F1 more than any model change. Grade F went from F1=0.00 to F1=0.82.
4/ GPU→CPU serialization is a real deployment gotcha. Models trained on Colab’s T4 GPU need to be moved to CPU before pickling — otherwise joblib fails silently on any CPU-only machine.
5/ Module structure matters for serving. Separating shared classes into model.py is what allows joblib to deserialize correctly when uvicorn serves the app.
6/ Docker makes deployment reproducible. The same image that runs locally runs identically in the cloud — no dependency surprises, no environment drift. This alone justified learning it.
7/ AI coding assistants are genuinely useful — but they also make confident, subtle mistakes. I used Claude throughout this project and it saved me hours. However, it also sent me down more than a few wrong paths. Knowing enough to catch those errors and course correct is exactly the kind of judgment that comes from real domain experience.
GitHub: https://github.com/jqchen24-new/lending-club-loan-grade-prediction
Huge thanks to Alexey Grigorev and the DataTalks.Club team for building something this good and keeping it free.
#MachineLearning #DataScience #PyTorch #MLOps #Docker #FastAPI #MLZoomcamp #DataTalksClub #LearningInPublic #containerization